Tags
- none
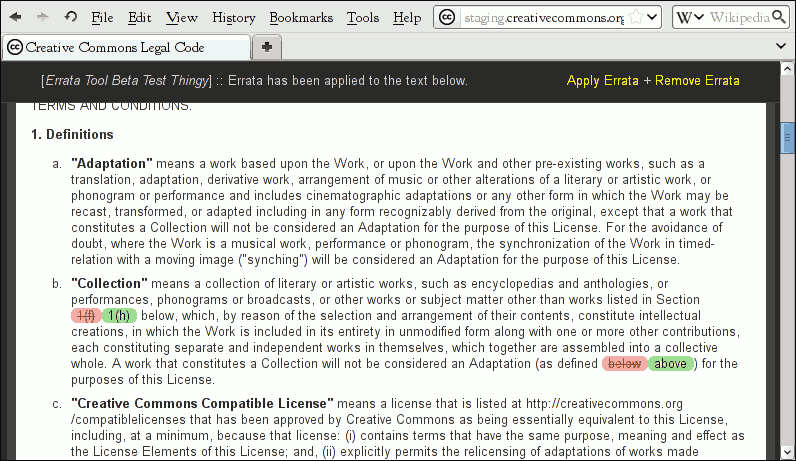
The html for the legalcode pages cannot be changed once they are published. The reason for this is because we provide sha1 hashes of them so that they may be redistributed. It also is a reason of credibility; that the license you've applied to your work today will still be the same one tomorrow. However, sometimes there are errors. They need to be accessible, yet they usually are too small to merit releasing a new version of the license.
The solution to this problem so far has been an errata page on our wiki. But, that isn't apparent from just looking at the license; and the errata page is disorganized and confusing to read.
I'm proud to say that we're currently testing a tool I wrote last week that will fix this problem: cc.legalerrata. This was originally intended to be implemented with the upcoming 4.0 licenses, but it turns out the 3.0 licenses have a hook for a tool like this already in place. The 3.0 licenses include a script at the address http://creativecommons.org/includes/errata.js, which was blank until a few days ago. Now the script is used to bootstrap an application in the page. Once bootstrapped, the tool queries the server for appropriate errata; if errata is returned, a toolbar appears and the user is presented with the option to apply the errata to the text of the page. Additionally, the changes made can be highlighted via the toolbar.
Currently, this tool is disabled on the live site while we verify that the machine readable errata is actually correct. You can however try out the tool while we test it, via our staging site. For example, you can try our BY-SA legalcode on staging here.
If you're interested, you can read the original proposal for the tool. There are two versions of the tool described there, and some pretty ui diagrams that I drew of both versions. Here is one of my diagrams:

The actual implementation of the tool ended up being much simpler than the proposed one. Json is still used for storing the machine readable errata, but rather than a convoluted scheme of managing text diffs, machine readable errata is a collection of entries that contain a css selector, attribute overrides (optional), and html fragments. The css selectors are used by jquery to select an element in the dom; the element's innerHTML attribute is then written over by the html fragment. The html fragment itself is the original innerHTML of the node, but with subtractions noted by tags, and additions noted by tags. These files are maintained by hand at this current time, with no plans of writing a frontend for it. The errata tool takes a snapshot of the page's html before and after overriding it, so that you can efficiently toggle between view modes. CSS in both errata modes to either make the text look clean (subtractions hidden) or to accomplish highlighting.