Creative Commons Awarded AWS Imagine Grant
community open-source cc-searchCreative Commons was recently awarded a $125,000 AWS Imagine grant, which will cover infrastructure costs associated with some of the key features we intend to add to CC Search in 2020. In particular, some of the key outcomes we hope to have achieved at the end of the year are:
- Machine-generated tags using cutting edge computer vision technology produced by Amazon Rekognition. In addition to surfacing metadata-sparse images in our catalog, we may be able to offer features like filtering by artistic medium (painting, photo, pencil sketch, etc).
- Produce CC-hosted thumbnails for every image instead of relying on third-party images, which are often suffer from unreliable availability, are resistant to embedding, or are otherwise too low quality for our purposes.
- Acquire knowledge of other features of images, such as their resolution or filesize. Since we often scrape links to images without any further processing, we rely on the data upstream providers give us, which is often missing this information.
Because cutting-edge computer vision typically requires specialized hardware and expertise, outsourcing this task to AWS ends up being economical in comparison to implementing it ourselves. Nonetheless, due to the volume of images we need to classify, this will take up a significant amount of the grant budget; we intend to hand-pick which data sources get tagged in order to make the best use of the resources available to us.
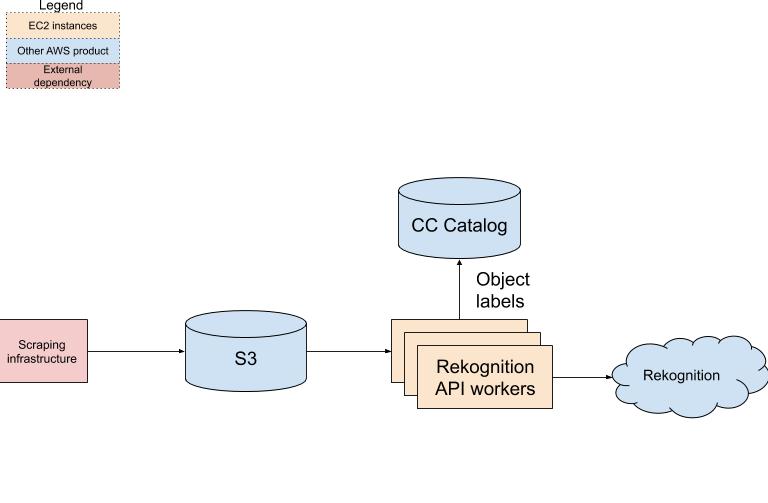
When we’re discussing computer vision, generating thumbnails and collecting resolution sounds comparatively mundane, but it is actually a significant technical challenge that will require a serious investment in infrastructure as well. For one thing, in order to feed images to Rekognition, we need to have a copy of the image in the first place, which you may be surprised to find that we currently do not! All of our content is hosted by the original third party sources and embedded in the search results page. Sometimes, we will sneakily proxy images through our own infrastructure (in cases where the source does not offer HTTPS or an appropriately sized thumbnail), but in most instances, we have to place complete trust in what the source makes available to us. This has lead to problems with availability. Nobody likes it when the images in their search results are inexplicably broken because a third-party datacenter is having issues. Using the funds from the grant, we will at the very least be able to generate thumbnails just before they are served to the user, and possibly even bulk thumbnail our catalog of 325 million images. That’s a huge task - there may very well be petabytes of image data to scrape.
In order to thumbnail and label our entire catalog, we are going to need to build some additional infrastructure. For the thumbnailing component, we intend to use Scrapy Cluster (composed of an MSK queue, an Elasticache instance, some utility EC2 instances for controlling the cluster and communicating between components, and a large cluster of EC2 instances running web scrapers) to build a distributed system for rapidly downloading and resizing images. A controller instance will feed image URLs into the job queue. Once the destination image URLs have been fed to the cluster, Scrapy Cluster dispatches the URLs to a scalable group of crawler bots, which fetch the image, collect some metadata (such as dimensions), resize the images, and then upload the thumbnails to S3 while pushing the new image metadata back to our image database on RDS. We will then be able to start serving up the thumbnails to our end users. While we initially plan to only use this cluster for producing thumbnails, we expect it could be valuable for discovering and indexing additional CC licensed content in the future. See below for a visualization of the distributed scraping and thumbnailing system.
Scraping and thumbnailing system:
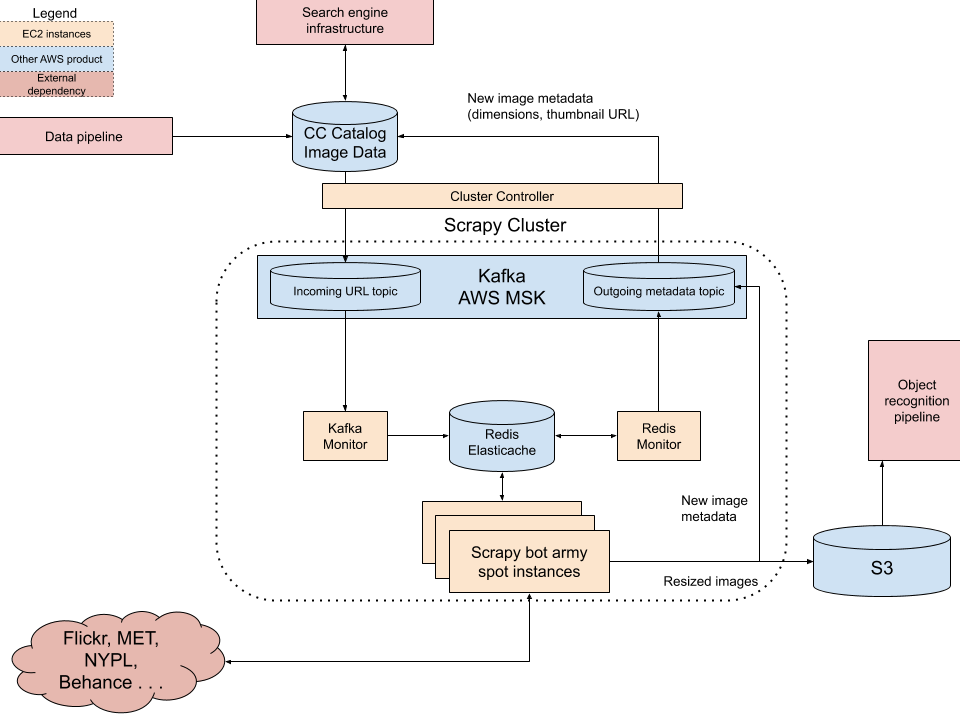
Image recognition pipeline: