CC Catalog: Leveraging Open Data and Open APIs
community open-source cc-search cc-catalogThis post is the first of a three-part series about the underlying infrastructure for Creative Commons (CC) Catalog and the efforts to increase the volume and variety of creative works.
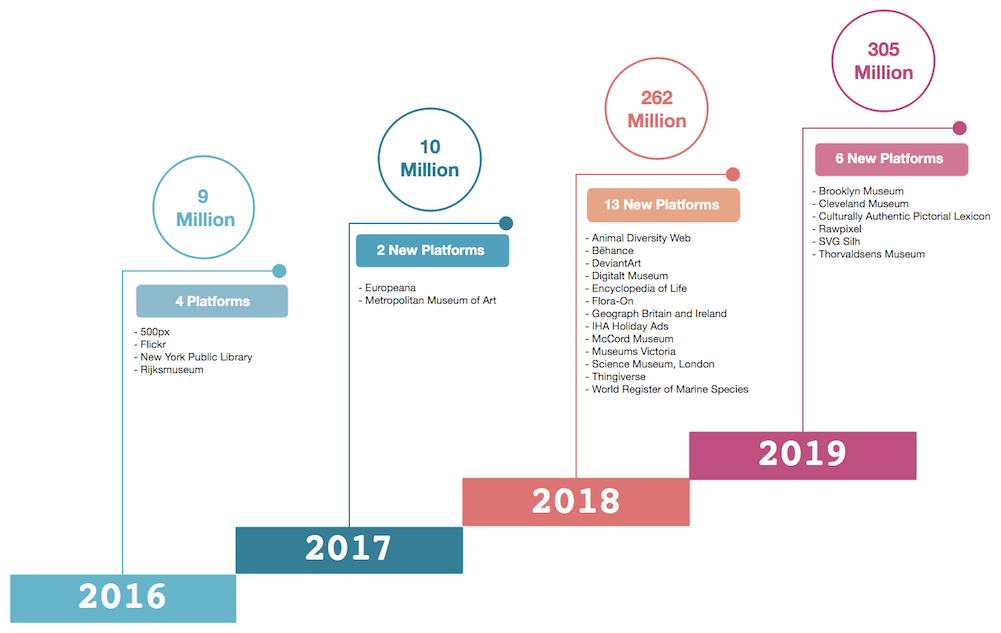
The purpose of CC Catalog is to facilitate the discovery of openly licensed content, that proliferates the web. However, this is a challenging task and it requires a combination of techniques. The initial efforts to catalog the Commons began in 2016. The goal was to identify approximately 1% of the estimated 1.4 billion works by harnessing open repositories and open APIs to build a front door to the Commons. Since then, there has been an emphasis on including more content and discovering new platforms. While CC Catalog still leverages open data to achieve the above, we needed to develop the appropriate infrastructure to also routinely update the existing data.
The development of this infrastructure began in 2018 with the first Common Crawl data pipeline. Apache Spark was used to streamline the processing of petabytes of web crawl data to identify all domains that link to a Creative Commons license. The first test of this strategy was successful and it was instrumental in increasing the number of images and added 13 new platforms for the updates to CC Search beta. It also provided incremental updates to the catalog on a monthly basis. Even though Common Crawl corpus is an invaluable source, it requires us to develop a custom parser for each platform that we integrate. This has its merits, but presents a few challenges.
After this, open APIs were explored and its purpose was not to replace the Common Crawl methodology but to augment it and hopefully increase the volume of data. This approach began with two platforms: 1) Flickr, since it has millions of CC license content and 2) Thingiverse. At the end of 2018, the exploratory efforts paid off and the catalog grew from 10 million images to over 260 million and the Flickr API was instrumental in achieving this. In early 2019, three new API providers were included: 1) Met Museum, 2) Cleveland Museum, and 3) Brooklyn Museum. This led to the development of our API ETL data pipeline that is managed by Apache Airflow.
Currently, we have over 305 million images from 25 providers, and we are still working to improve the data infrastructure and solidify our efforts for building a vibrant, usable Commons.
The above data is made available to CC Search via CC Catalog API. However, all providers in the catalog are not immediately available in CC Search. Various preprocessing efforts are performed in the back-end by the CC Catalog API to determine which content is deemed ready for publishing. Also, platforms are subject to additional reviews and may be suppressed until that process has completed. Currently, CC Search has 19 of the above providers comprising over 300 million images.
The goal for 2019 is to increase the catalog to:
- 325 million images
- 30 providers
- add new content types
The next post will discuss the details of the Common Crawl data pipeline and how instrumental this corpus is for identifying potential providers and understanding how people are using the various CC license.