Automating Quantifying the Commons: Part 1
gsoc-2024 gsoc big-data quantifying-the-commons cc-software open-source community
Introduction
Quantifying the Commons, an initiative emerging from the UC Berkeley Data Science Discovery Program,
aims to quantify the frequency of open domain and CC license usage for future accessibility and analysis purposes
(Refer to the initial CC article for Quantifying here!).
To date, the scope of the previous project advancements has not included automation or combined reporting,
which is necessary to minimize the potential for human error and allow for more timely updates,
especially for a system that engages with substantial streams of data.
As a selected developer for Google Summer of Code 2024, my goal this summer is to develop automation software for data gathering, flow, and report generation, ensuring that reports are never more than 3 months out-of-date. This blog post serves as a technical journal for my endeavor till the midterm evaluation period. Automating Quantifying the Commons: Part 2 will be posted after successful completion of the entire summer program.
Pre-Program Knowledge and Associated Challenges
As an undergraduate CS student, I had not yet had any experience working with codebases as intricate as this one; the most complex software I had worked on prior to this undertaking was most probably a medium-complexity full-stack application. In my pre-GSoC contributions to Quantifying, I did successfully implement logging across all the Python files (PR #97), but admittedly, I was not familiar with a lot of the other modules that were being used in these files. As a result, this caused minor inconveniences to my development process from the very beginning. For example, not being experienced with operating system (OS) modules had me confused as to how I was supposed to join new directories. In addition, I had never worked with such large streams of data before, so it was initially a challenge to map out pseudocode for handling big data effectively. The next section elaborates on my development process and how I resolved these setbacks.
Development Process (Midterm)
I. Data Flow Diagram Construction
Before starting the code implementation, I decided to develop a Data Flow Diagram (DFD), which provides a visual representation of how data flows through a software system. While researching effective DFDs for inspiration, I came across a technical whitepaper by Amazon Web Services (AWS) on Distributed Data Management, and I found it very helpful in drafting my own DFD. As I was still relatively new to the codebase, it helped me simplify the current system into manageable components and better understand how to implement the rest of the project.
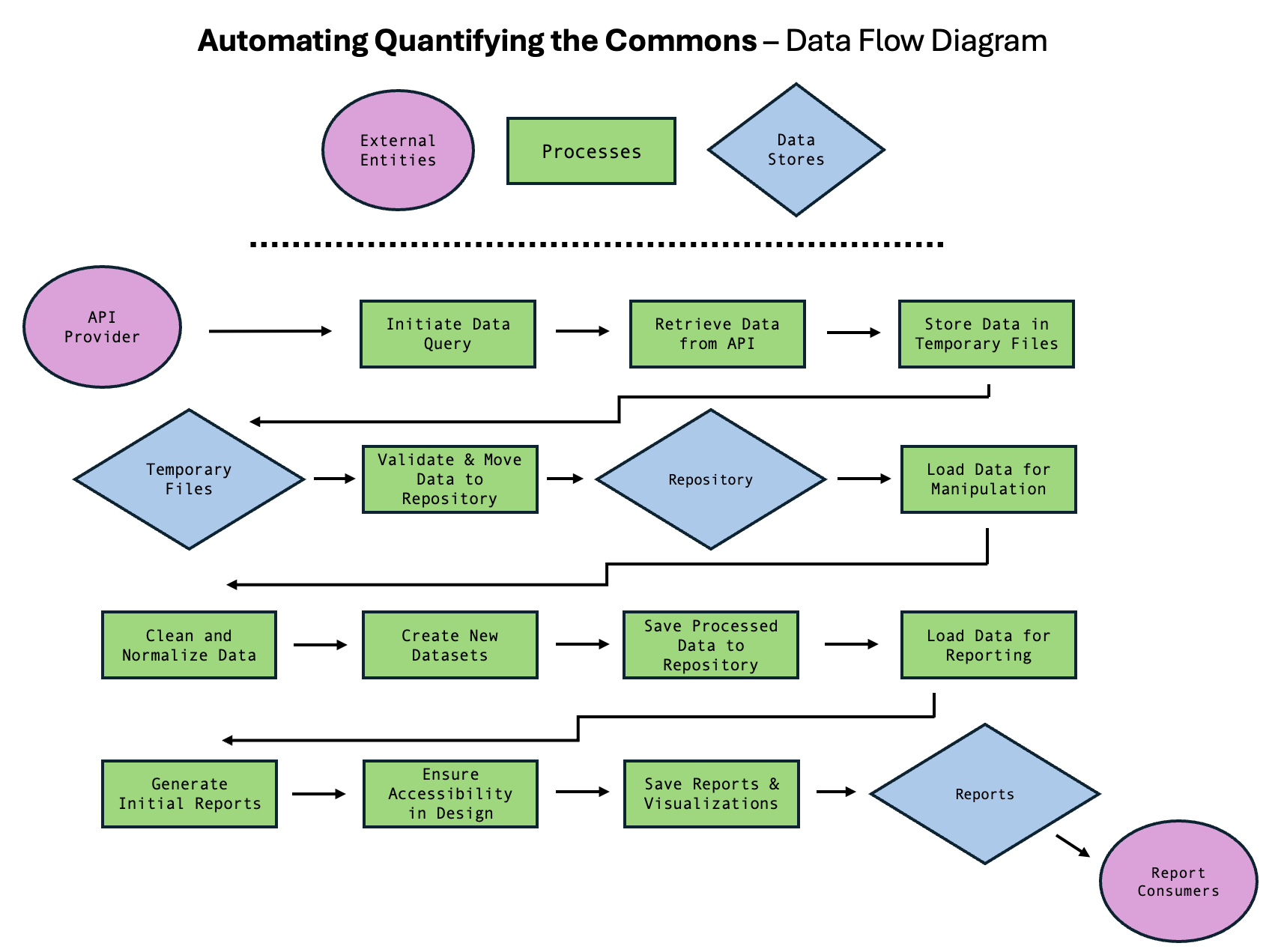 This was the initial layout for the data directory flow; however, the more I delved into the development process,
the more the steps changed. I will present the final directory flow in Part 2 at the end of the program.
This was the initial layout for the data directory flow; however, the more I delved into the development process,
the more the steps changed. I will present the final directory flow in Part 2 at the end of the program.
II. Identifying the First Data Source to Target
The main approach for implementing this project was to target one specific data source and complete its data extraction, analysis, and report generation process before adding more data sources to the codebase. There were two possible strategies to consider: (1) work on the easier data sources first, or (2) begin with the highest complexity data source and then add the easier ones later. Both approaches have notable pros and cons; however, I decided to adopt the second strategy of starting with the most complex data source first. Although this would take slightly longer to implement, it would simplify the process later on. As a result, I began implementing the software for the Google Custom Search data source, which has the largest number of data retrieval potential among all the other sources.
III. Directory Setup + Code Implementation
Based on the DFD, Timid Robot (my mentor) and I identified the directory process to be as such: within our scripts directory, we would have
separate sub-directories to reflect the phases of data flow, 1-fetch, 2-process, 3-report. The code would then be
set up to interact between systems in chronological order. Additionally, a shared directory was implemented to optimize similar functions and paths.
1-fetch
As I mentioned in the previous sections, starting to code the initial file was a challenge, as I had to learn how to use new technologies and libraries on-the-go. As a matter of fact, my struggles began when I couldn't even import the shared module correctly. However, slowly but surely, I found that consistent research of available documentation as well as constant insights from Timid Robot made it so that I finally understood everything that I was working with. There were a few specific things that helped me especially, and I would like to share them here in case it helps any software developer reading this post:
Reading Technical Whitepapers: As I mentioned earlier, I studied a technical whitepaper by AWS to help me design my DFD. From this, I realized that consulting relevant whitepapers by industry giants to see how they approach similar tasks helped me a lot in understanding best practices to implementing the system. Here is another resource by Meta that I referenced, called Composable Data Management at Meta (I mainly used the Building on Similarities section to study the logical components of data systems).
Referencing the Most Recent Quantifying Codebase: The pre-automation code that was already implemented by previous developers for Quantifying the Commons was the closest thing to my own project that I could reference. Although not all of the code was relevant to the Automating project, there were many aspects of the codebase I found very helpful to take inspiration from, especially when online research led to a dead end.
Writing Documentation for the Code: As a part of this project, I assigned myself the task of developing documentation for the Automating Quantifying the Commons project (can be accessed here!). Heavily inspired by the "rubber duck debugging" method, where explaining the code or problem step-by-step to someone or something will make the solution present itself, I decided to create documentation for future developers to reference, in which I break down the code step-by-step to explain each module or function. I found that in doing this, I was able to better understand my own code better.
As for the license data retrieval process using the Google Custom Search API Key,
I did have a little hesitation running everything for the first time.
Since I had never worked with confidential information or such large data inputs before,
I was scared of messing something up. Sure enough, the first time I ran everything with the language and country parameters,
it did cause a crash, since the API query-per-day limit was crossed with one script run. As I continued to update
the script, I learned a very useful trick when it comes to handling big data:
to avoid hitting the query limit while testing, you can replace the actual API calls
with logging statements to show the parameters being used. This helps you
understand the outputs without actually consuming API quota, and it can help you identify bugs more easily.
A notable aspect of this software is the directory organization. Throughout the process, I designed it so that the datasets are automatically stored within their respective quarter's directories rather than being stored altogether. This ensures efficient organization in order for users to easily access in the future, especially when the number of datasets multiplies.
Upon successful completion of basic data retrieval and state management in Phase 1, I felt much more confident about the trajectory of this project, and implementing future steps and fixing new bugs became progressively easier.
2-process
The long-term goal of the Quantifying project is to have comprehensive datasets for each quarter, encompassing
license data that scales up to millions and even billions. For the 2-process phase specifically, the aim is
to analyze and compare data between quarters to be able to display in the reports. However, given our Google Custom Search
API constraints as well as the time period we're working with for the GSoC period (most of this period is mainly
2024Q3), it is not possible to have a fully completed Phase 2. However, in order to deploy as complete of an automation software as possible,
I have set up a basic psuedocode that can be implemented
and built upon by future development efforts as more data is collected in the upcoming quarters/years.
3-report
As mentioned earlier, the Google Custom Search API constraints made it difficult to create a comprehensive and detailed dataset, so I plan to initiate the development of a more fletched-out Google Custom Search post-GSoC, when more data can be accumulated (discussed further in the next section). As of now, there are three main completed report visualization schemes: (1) Reports by Country, (2) Reports by License Type, and (3) Reports by Language. Although the visualizations are basic in design, I made sure to incorporate accessibility into the visualizations for a better user experience. This included adding elements like labels on top of the bars with specific number counts for better readability and understanding of the reports. In addition, I included three key features in the reports codebase to cater to various possible needs of the report users.
- Key Feature #1: I implemented command line arguments in which users can choose any quarter to visualize, as I believe this would be useful for anyone in need of individual reports from previous quarters, not just reports from this quarter.
- Key Feature #2: Successfully stores reports into the data reports directory specific to each quarter for optimal organization (similar to the dataset organization in Phase 1). In this way, reports from one quarter will not be mixed up with reports from another quarter, making it easier for users to navigate and use.
- Key Feature #3: The program automatically generates and/or updates an individual
READMEfile for each quarter's reports. ThisREADMEorganizes all generated report images within that quarter into one page, alongside basic report descriptions.
Mid-Program Conclusions and Upcoming Tasks
Overall, my understanding and skillset for this project increased ten-fold after completing all the phases for Google Custom Search.
Going into the second half of the Google Summer of Code program, I expect that I will complete the future data sources at a more efficient and faster rate,
given the license data sizes and my heightened expertise. In fact, as of now (the midterm evaluation point), I have completed
a relatively detailed Phase 1 for Flickr, which only involves 10 licenses. My biggest takeaway from the first half of the coding period is that rather than developing
a basic querying process and adding on later, it's easier to start off with a complex and detailed version before moving on to Phases 2 and 3. Additionally, using
the shared module within the scripts can be very beneficial to simplify the coding process.
In the second half of the GSoC program, I plan to keep both of these takeaways in mind when developing scripts for the rest of the data sources. On a formal level, the final goal for the end of GSoC 2024 is to have a working codebase for Phases 1, 2, and 3 of all data sources, including a completed automation setup for these scripts. Due to the effectiveness of the current directory organization and report generation features, I will be standardizing them across all data sources.
Finally, after the software is complete to the extent that is possible during the GSoC period, I plan to raise issues in the repository respective to all the next steps that could be taken post-GSoC by open-source developers for a more comprehensive software system.
So far, my journey at Creative Commons has significantly enhanced my skillset as a software developer, and I have never felt more motivated to take on more challenging tasks. I'm looking forward to more levels of growth and accomplishments in the second half of the program. I'll be back with Part 2 at the end of the summer with an updated, completed project!
Additional Readings
- Automating Quantifying the Commons: Part 2 | Author: Naisha Sinha | Aug. 2024
- Data Science Discovery: Quantifying the Commons | Author: Dun-Ming Huang (Brandon Huang) | Dec. 2022