CC Catalog: wrapping up GSoC20
cc-catalog gsoc gsoc-2020With the summer of code coming to an end, this blog post summarises the work done during the last three months. The project I have been working on is to add more provider API scripts to the CC Catalog. The CC Catalog project is responsible for collecting CC licensed images hosted across the web.
The internship journey has been great , and I was glad to get the opportunity to understand more about the working of the data pipeline. My work during the internship mainly involved researching new API providers and checking if they meet the necessary conditions, then we decided on a strategy to crawl the API. The strategy varies according to different APIs: some can be partitioned based on date, others have to be paginated . Script is written for the API according to the strategy. During the later phase of the internship, I had worked on the reingestion strategy for europeana and a script to merge Common Crawl tags and metadata to the corresponding image in the image table.
Provider API implemented :
- Science Museum : Science Museum collection has around 60,000 images and was initially crawled through Common Crawl and shifted to API based crawl.
- Issue: Science Museum ticket
- Related PRs: Science Museum script, Science Museum workflow
- Statens Museum : Statens Museum for Kunst is Denmark’s leading museum for artwork . This is a new integration and 39115 images have been collected.
- Issue: Statens Museum ticket
- Related PRs: Statens Museum implementation
- Museums Victoria : It was initially ingested from Common Crawl later shifted to API based crawl. It has around 140,000 images.
- Issue: Museums Victoria ticket
- Related PRs: Museums Victoria implementation
- NYPL : New York Public Library is a new integration , as of now it has around 1296 images.
- Issue: NYPL ticket
- Related PRs: NYPL implementation
- Brooklyn Museum : This was an existing integration , changes were made to follow the new
ImageStoreandDelayedRequestorclass , it has 61503 images.- Issue: Brooklyn Museum ticket
- Related PRs: Brooklyn Museum implementation
Iconfinder is a provider of icons that could not be integrated as the current strategy of ingestion is very slow and we need a better strategy.
- Issue : Iconfinder ticket
Europeana reingestion strategy
Data collected from europeana was collected on a daily basis and there was a need to refresh it. The idea is that new data should be refreshed more frequently and as the data gets old, refreshing should become less frequent. While developing the strategy the API key limit and maximum collection expected is to be kept in mind. Considering these factors, a workflow was set up such that each day it crawls 59 days of data. The 59 days were split up into layers. The DAG crawls daily up to 1 week old data then it crawls monthly for data more than 1 week old and less than a year old data, anything older than a year is crawled every 3 months.
- Issue: Europeana reingestion ticket
- Related PR: Europeana reingestion strategy
More details regarding the math of reingestion: Data reingestion

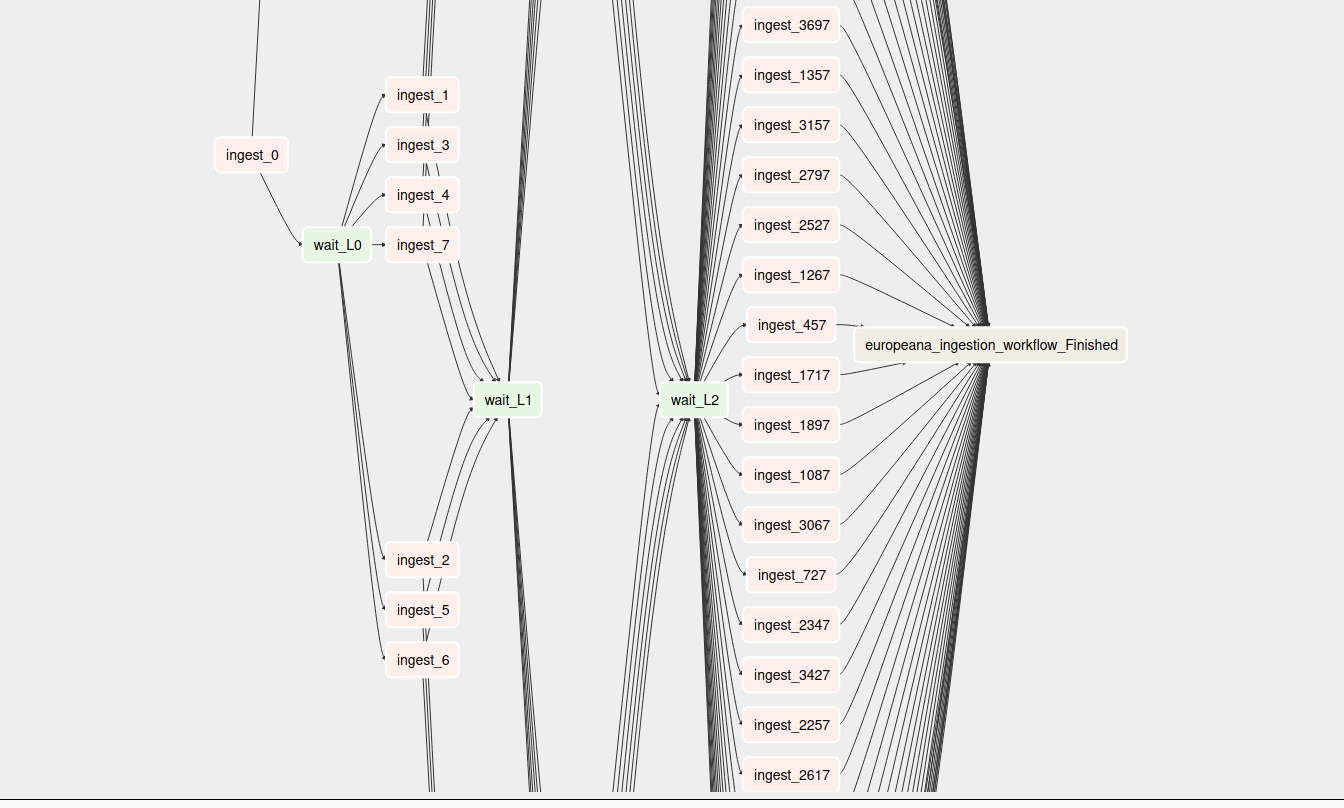
Europeana reingestion workflow
Merging Common Crawl tags
When a provider is shifted from Common Crawl to API based crawl, the new data from API doesn’t have tags and metadata that were generated using clarifai and hence there is need to associate the new data with the tags corresponding to that image from the Common Crawl data. A direct url match is not possible as the Common Crawl urls and API image url are different, so we try to match it on the number or identifier that is associated with the url.
Currently the merging logic is applied to Science Museum, Museums Victoria and Met Museum .
In Science Museum, API url in image table is like https://coimages.sciencemuseumgroup.org.uk/images/240/862/large_BAB_S_1_02_0017.jpg and CC url is like https://s3-eu-west-1.amazonaws.com/smgco-images/images/369/541/medium_SMG00096855.jpg . So the idea is to reduce the url to the last identifier like number , so after the modification of the url by modify_urls function it looks like gpj.1700_20_1_S_BAB_ (API url) and gpj.55869000GMS_ (CC url) .
Similar logic has been applied to met museum and museum victoria.
{kind=link}
{kind=link}
- Issue: https://github.com/cc-archive/cccatalog/issues/468
- Related PR: https://github.com/cc-archive/cccatalog/pull/478
Acknowledgement
I would like to thank my mentors Brent and Anna for their guidance throughout the internship.