Data flow: from API to DB
cc-catalog airflow gsoc gsoc-2020Introduction
The CC Catalog project handles the flow of image metadata from the source or provider and loads it to the database, which is then surfaced to the CC search tool. The workflows are set up for each provider to gather metadata about CC licensed images. These workflows are handled with the help of Apache Airflow. Airflow is an open source tool that helps us to schedule and monitor workflows.
Airflow intro
Apache Airflow is an open source tool that helps us to schedule tasks and
monitor workflows . It provides an easy to use UI that makes managing tasks
easy. In Airflow, the tasks we want to schedule are organised in DAGs
(Directed Acyclic Graphs). DAGs consist of a collection of tasks, and a
relationship defined among these tasks, so that they run in an organised
manner. DAGs files are standard python files that are loaded from the defined
DAG_FOLDER on a host. Airflow selects all the python files in the
DAG_FOLDER that have a DAG instance defined globally, and executes them to
create the DAG objects.
CC Catalog Workflow
In the CC catalog, Airflow is set up inside a docker container along with other
services . The loader and provider workflows are inside the dags directory in
the repo dag folder. Provider workflows are set up to pull metadata
about CC licensed images from the respective providers , the data pulled is
structured into a standardised format and written into a TSV (Tab Separated
Values) file locally. These TSV files are then loaded into S3 and then finally
to PostgreSQL DB by the loader workflow.
Provider API workflow
The provider workflows are usually scheduled in one of two time frequencies, daily or monthly.
Providers such as Flickr or Wikimedia Commons that are filtered using the date parameter are usually scheduled for daily jobs. These providers have a large volume of continuously changing data, and so daily updates are required to keep the data in sync.
Providers that are scheduled for monthly ingestion are ones with a relativley low volume of data, or for which filtering by date is not possible. This means we need to ingest the entire collection at once. Examples are museum providers like the Science museum UK or Statens Museum for Kunst. We don’t expect museum providers to change data on a daily basis.
The scheduling of the DAGs by the scheduler daemons depends on a few parameters.
start_date- it denotes the starting date from which the task should begin running.schedule_interval- it denotes the interval between subsequent runs, it can be specified with airflow keyword strings like “@daily”, “@weekly”, “@monthly”, “@yearly” other than these we can also schedule the interval using cron expression.
Example: Cleveland museum is currently scheduled for a monthly crawl with a
starting date as 2020-01-15. cleveland_museum_workflow
Loader workflow
The data from the provider scripts are not directly loaded into S3. Instead, they are stored in a TSV file on the local disk, and the tsv_postgres workflow handles loading of data to S3, and eventually PostgreSQL. The DAG starts by calling the task to stage the oldest tsv file from the output directory of the provider scripts to the staging directory. Next, two tasks run in parallel, one loads the tsv file in the staging directory to S3 , while the other creates the loading table in the PostgreSQL database. Once the data is loaded to S3 and the loading table has been created, the data from S3 is loaded to the intermediate loading table and then finally inserted into the image table. If loading from S3 fails the data is loaded to PostgreSQL from the locally stored tsv file. When the data has been successfully transferred to the image table, the intermediate loading table is dropped and the tsv files in the staging directory are deleted. If the copying the tsv files to S3 fails or then those files are moved to the failure directory for future inspection.
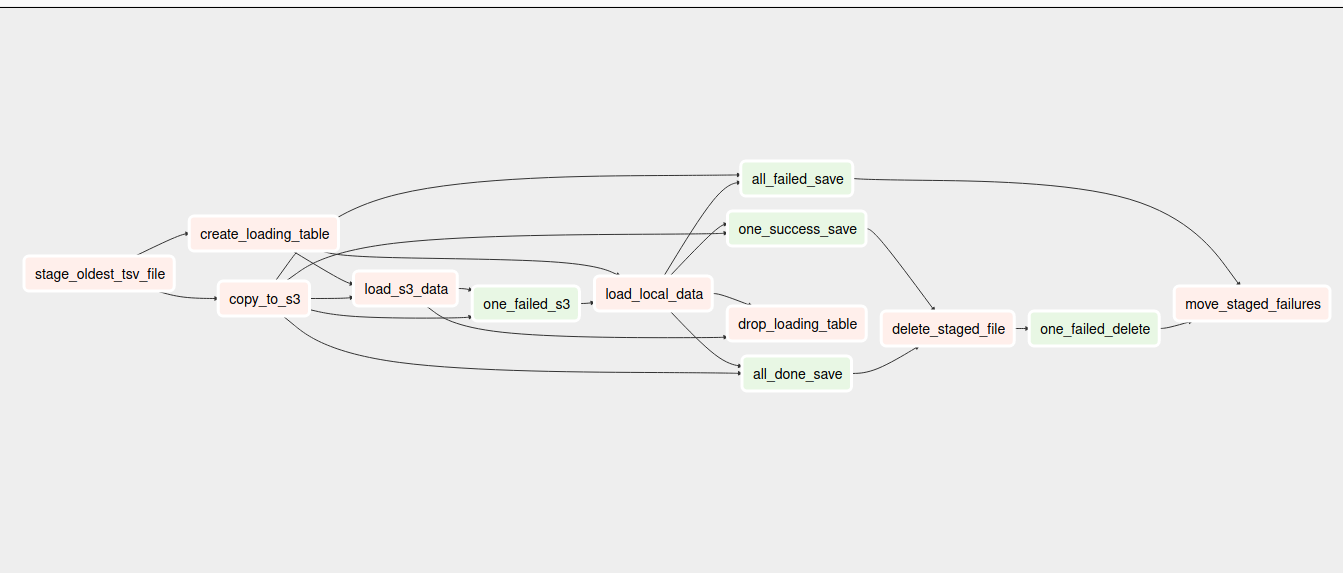
Loader workflow
Acknowledgement
I would like to thank Brent Moran for helping me write this blog post.