ℹ️ 2023-08-31: This project was archived along with the shuttering of CC
Search (now Openverse). Please also see the
Quantifying the Commons
project.
This is a continuation of my last blog post about the data processing part of the CC-data catalog visualization project. I recommend you to read that last post for a better understanding of what I'll explain here.
The data
Every dataset needs cleasing and pre processing operations before their analysis. In order to implement validations, I have to know first with what kind of inconsistencies I would deal with. Here are some interesting insights about the dataset:
- There are several cases where the provider_domain has not referenced a correct cc_license path. We might say then, that not everybody has a clear understading of how to give CC license attributions correctly.
- I found a case where the links json was malformed. It had a huge paragraph as key (instead of a domain). I wasn't expecting something like that hehe.
- There are both types of entries, a provider domain with a small image quantity and a lot of links, and with a huge amount of images but few links. Some of the domains with a lot of images belong to online shops or news websites.
Aside from the above, I have had to face with almost empty lines(meaning just a single column had information), columns bad separated (not a single but more than one tab between the columns), and some other usual problems of a real and non perfect dataset. I have made validations to catch these inconsistencies.
Data aggregation
It is needed to aggregate the data by provider_domain, in order to get the complete information of every node. Aggregating the images column is simple, as I only have to sum the values in that column. Now the links column is a little bit tricky to be aggregated. We have to remember that this field contains dictionaries, with domains as keys and the times they have been referenced to as values. So for aggregating this column, I need to:
- Create an empty dictionary
- Loop through every key and save it
- If I face with a key that is already in the dictionary, just sum the value that I currently hold to the existing value in the dictionary.
Then, I have to extract creativecommons from the final links dictionary, and put the value into another column, called _Licences_qty_. This is because the quantity of links to creativecommons.org can tell us how many licenses the provider_domains uses.
We also need to aggregate the licences column. The goal is to have a data structure that contains the licenses types the provider_domain uses, and to know how many licenses per each license type the provider_domain has.
To achieve this, I:
- Create an empty dictionary of licences
- For each license, create a tuple (license_name,version), which will be a key in the dictionary
- Check if the key exists in the dictionary. If it doesn't, the key is added, with an initial value of 1, to the dictionary.
- If the key exists, increment the value in 1.
At the end, we will have rows like the following:
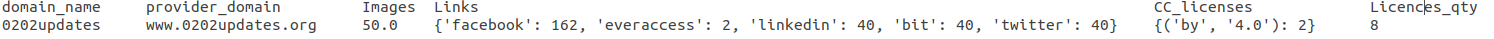 Example row, with data aggregated.
Example row, with data aggregated.
Considerations and future challenges
I mentioned before that there are provider domains with a lot of images and a few links, and vice versa. As I still have to prune and filter data, I can develop a rule to exclude the domains that are not relevant to the graph. This relevance can be determined by the quantity of images and/or links. My thought with the rules are the following:
- Exclude domains that have a lot of images but few links (less than 20 links).
- Exclude domains that have few images(less than 100) and few links (less than 20)
- Exclude domains that have no links (is not a targeted node).
- Exclude domains that are social networks (Facebook, Instagram, Twitter), as they might not give relevant insights. Most of the references to these SN's are found because the provider domain gives the user the option to share a content.
The thresholds for the quantity of images and links are my intuitions from having seen the data and manually checking some provider domains. If it is possible I could validate it with some data analysis (checking average, maximum and minimum values of the columns).
Coming soon
- Extraction of unique nodes, and links.
- Visualization with the data.
- Development or modification of pruning/filtering rules.
You can follow the project development in the Github repo.
CC Data Catalog Visualization is my GSoC 2019 project under the guidance of Sophine
Clachar, who has been greatly helpful and considerate since the GSoC application period. Also, my backup mentor, Breno Ferreira, and engineering director Kriti
Godey, have been very supportive.
Have a nice week!
Maria