Automating Quantifying the Commons: Part 2
gsoc-2024 gsoc big-data quantifying-the-commons cc-software open-source community
Introduction: Midterm Recap
This post serves as a technical journal for the development process of the concluding stretch of Automating Quantifying the Commons, a project initiative for the 2024 Google Summer of Code program. Please visit Part 1 for more context if you haven't already done so.
At the point of the midterm evaluation, I successfully completed Phases 1, 2, and 3
(fetch, process, and report) of the Google Custom Search (GCS) data source, with a working report README generation
for each quarter. My documented goal for the second half of the period was to complete a baseline automation
software for these processes across all data sources.
Development Process
I. Midpoint Reassessment
If you read my previous post, you might have seen that my next steps involved completing the phases for the remaining data sources. However, I soon realized that the GCS phases, along with the base analysis and visualization code from the Data Discovery Program, already serve as a standard reference for these tasks. Given that the primary goal of this project is to develop automation software for these phases, my mentor suggested shifting the focus of the final time period towards programming the Git functions for automation. This approach, which will require more time and effort, will ensure that anyone working on the remaining data sources can easily integrate them using the existing code as a reference.
II. GitHub Actions Development
We defined GitHub Actions to host our CI/CD workflows, and since I had never used YAML before, I needed to learn and familiarize myself with this new technology. Learning YAML presented challenges, particularly in developing the Git automation. My mentor emphasized focusing on the Git programming due to these challenges. For example, I encountered errors during workflow runs without clear ways to debug them.
In my previous post, I shared three strategies that helped me familiarize myself with new technology during the first half of the summer. Here, I’m sharing two additional strategies that were particularly useful for GitHub Actions programming:
GitHub Actions Extension for Visual Studio Code: As I was using VSCode for development, I initially struggled to debug issues during workflow runs. Discovering the GitHub Actions Extension for VSCode was a game-changer. This extension highlights issues in the workflow, making it much easier to diagnose and fix problems. I highly recommend searching extensions for any development task, as having relevant tools can make programming much easier.
Creating Mini-Tasks for Experimentation: I set up my own GitHub repository with minimal, functional code to experiment with GitHub Actions in a low-risk environment. This approach facilitated easier debugging and comparison, helping me understand why certain things weren’t working. Although I gained more repository privileges after being accepted for GSoC, I still didn’t have the same access level as my mentor. By using a separate repository, I gained a better understanding of GitHub Actions and was able to interpret error logs more effectively. For instance, I realized that the automation wasn’t working initially due to outdated repository secrets, which I discovered without access to the secrets.
After successfully compiling the initial steps, I focused on refining the scripts for optimal performance. I moved the commit functions into a shared module, which reduced the risk of crashes by allowing functions to be called within individual scripts rather than directly in the YAML workflow. Once the workflows ran successfully, I implemented Cron functions to schedule them quarterly.
III. Engineering a Custom Error Handling and Exception System
A key innovation in this project was the creation of a custom QuantifyingException class tailored specifically for the unique needs of the data pipeline.
Unlike generic exceptions, this specialized exception class was designed to capture and handle errors that are particular to the Quantifying process, such as data inconsistencies,
API rate limits, and file handling errors. By centralizing these exceptions within QuantifyingException, I ensured that all three phases could consistently manage errors in a coherent and structured manner.
While testing this system across all phases, I made sure to purposely include "edge-case" errors upon commits to guarantee that the system could handle all these errors.
Upon completion of a robust error and exception handling system, I completed all phase outlines of the remainder of the data sources. For fetching data from these sources, I have developed codebases combining the GCS fetch system and the original Data Discovery API fetching for a complete fetching system. However, it should be noted that I have not actually fetched data from these APIs using the new codebase, as Timid Robot will undertake an initiative to add GitHub bots for the API keys after the GSoC period — this is due to best practice purposes, as it is fundamental to create dedicated accounts for clear API usage and automated git commits. Therefore, these fetch files may need to be slightly tweaked after that, which will be discussed in Next Steps. However, I have made sure to utilize fake data to ensure that the third phase successfully generates reports within the respective README file for ALL data sources.
IV. Finalized Flow of System + Data
In Part 1, I had shared the initial data flow diagram (DFD) for arranging the codebase. By the end of the program, however, the DFD and the overall system had solidified into something different. Below is the final diagram for data flow, which establish an official framework for future endeavors.
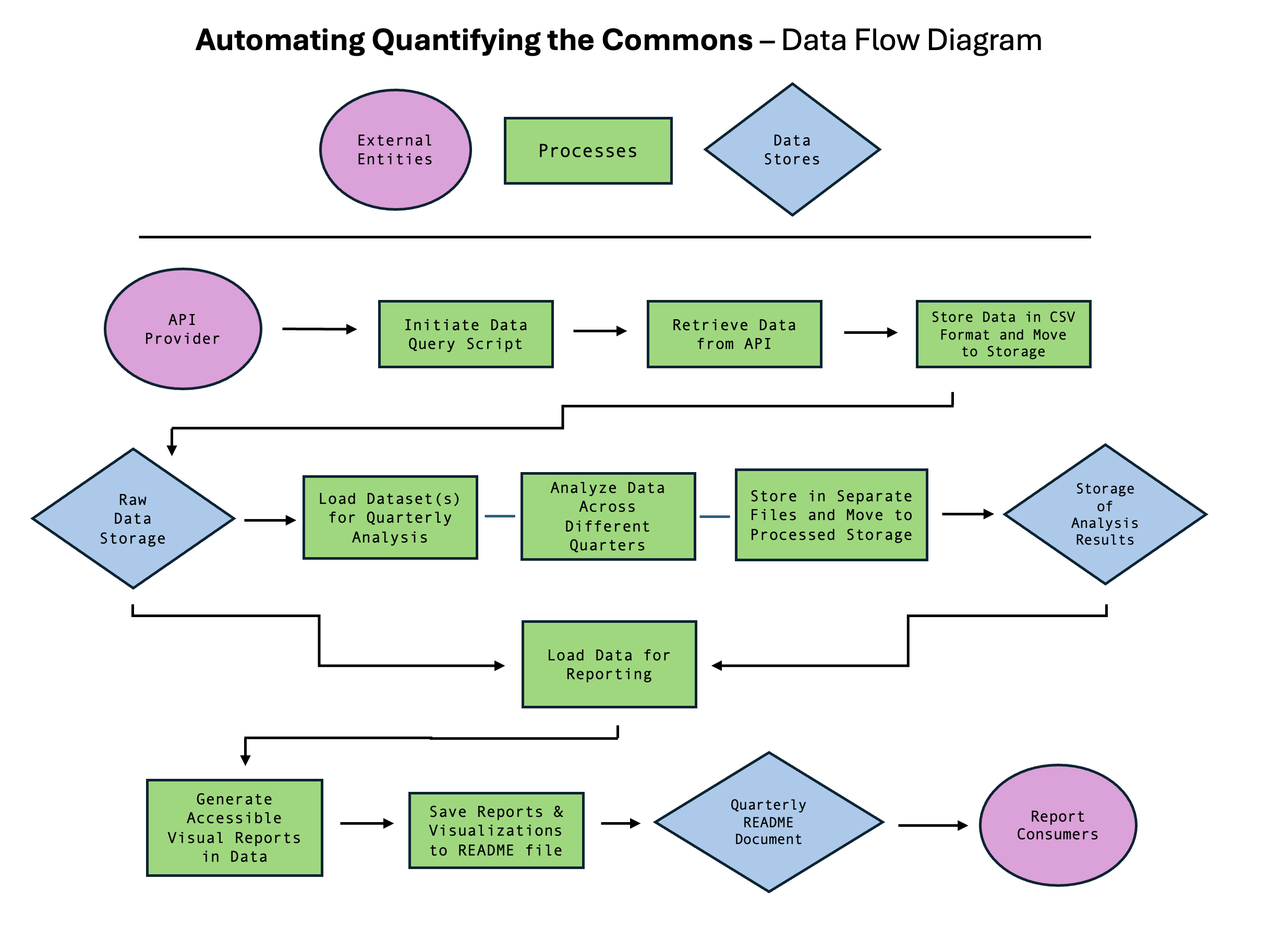
Final Conclusions
I. All Deliverables Completed Over the Course of the Program
Although this 12-week period allowed significant expansion of the Quantifying codebase, there were still time and resource constraints that we had to consider; primarily, the lack of data we could collect using the given APIs over this time period. However, as mentioned earlier, given strategic implementations, I was able to still complete the summer goal of developing a baseline automation software for data gathering, flow, and report generation, ensuring script runs on a quarterly basis. The Next Steps section will elaborate on how this software will be solidified over the upcoming quarters and years.
130+ commits, 7,615+ net code additions, and 360+ hours of work later, I present ten pivotal deliverables that I have completed over the summer period:
| Deliverable | Description |
|---|---|
| Phase 1: Fetch Data | Building on previous efforts in the Quantifying initiative, this phase efficiently fetches raw data from various data sources using APIs. The retrieved data is then stored in a structured CSV format, preparing it for processing and analysis. |
| Phase 2: Process Data (Outline) | This phase focuses on analyzing the fetched data between quarters. Since only 2024Q3 data (07/01/2024 - 09/30/2024) could comprehensively be generated during the summer period, a psuedocode outline of analysis was developed. Although this phase will be further solidified as more quarters and years pass by, a base error system was tested and implemented during the GSoC period to ensure thoroughness for this phase. |
| Phase 3: Generate Reports | The final phase successfuly creates visualizations and reports based on the generated datasets. These reports are designed to present key findings and trends in a clear, concise manner, and have been designed to automatically be integrated into a quarterly README file to provide a comprehensive overview of license data across data sources. |
| Shared Module | Created a singular, shared module to organize and streamline the codebase, allowing different directories, paths, and components to be imported through that module across different files. |
| Directory Sequence (OS) | Using Operating System (OS) Modules, the codebase effectively facilitates the interaction between all three phases, ensuring smooth communication of 10 different data sources with their respective data storages. |
| Automation using GitHub Actions CI/CD | All three phases of the project — data fetching, processing, and reporting — have been automated using YAML scripts in GitHub Actions. This CI/CD pipeline ensures that every update to the codebase triggers the entire workflow, from data retrieval to the generation of final reports, maintaining consistency and reliability across the process. Cron functions are used to ensure that these scripts are run every quarter in a timely manner. |
| Custom Error & Exception Handling System | Implemented a custom exception system that centralizes the error-handling logic, keeping the codebases more specific, maintainable, and consistent overall. This system has been thoroughly tested and verified across all three phases. |
| Project Directory Tree | Added a structured layout of the project (hierarchical representation of directories and files with descriptive comments), which provides developers with a clear understanding of the project's organization and help them navigate through different components easily. |
| Data Flow + System Design | Finalized an overall data flow and system design diagram to establish an official framework for the codebase. |
| Comprehensive Documentation | This document was developed to serve as a reference guide for any contributors having questions or needing detailed clarification on specific topics within the Quantifying codebase — each section has its own page with expanded information. It also includes external references and documentation regarding the languages and tools used for this project. |
II. Acknowledgements, Impact, Next Steps
This project would not have been possible without the constant guidance and insights of my mentors: Timid Robot Zehta (lead), Shafiya Heena (supporting), and Sara Lovell (supporting). I appreciate how they created a safe space for working since the very beginning. I've never felt hesitant to ask questions and have never felt out-of-place working in the organization, despite my introductory-level skillset at the start. In fact, this allowed me to feel open to ask questions and be able to undertake side-projects that facilitated my growth. I truly believe that being able to work in an environment like this has played a large role in my ability to perform well, and this was the sole reason for the overall fast progress and depth of my deliverables.
As for overall impact, it is very evident that Creative Commons is integral to facilitating the sharing and utilization of creative works worldwide. With over 2.5 billion licenses globally, Creative Commons and its open-source inititives hold heavy impact, promising to empower researchers, policymakers, and stakeholders with up-to-date insights into the global usage patterns of open doman and CC-licensed content. Therefore, I'm looking forward to witnessing the direct influence this project holds in paving the way for future advancements in leveraging open content licenses globally. I am extremely grateful and honored to be able to play such a major role in contributing to this organization, and am excited to see future contributions I facilitate alongside other CC open-source developers.
As for next steps, I am opening several post-GSoC issues in the Quantifying repository that can be worked on by any open-source contributor. These issues cover some of the necessary adjustments that need to be made once we cross certain time periods and codebase additions. If you're interested in getting involved, please visit the Issues page linked for your convenience. Your contributions will be invaluable as we continue to enhance and expand this project, and I’m eager to see the innovative solutions and improvements that will unfold these upcoming years!
Additional Readings
- Automating Quantifying the Commons: Part 1 | Author: Naisha Sinha | Jul. 2024
- Data Science Discovery: Quantifying the Commons | Author: Dun-Ming Huang (Brandon Huang) | Dec. 2022