The following blog intends to explain the very recent feature integrated to the Linked Commons. Be it the giant Google Search or any small website having a form field, everyone wishes to predict what’s on the user’s mind. For every keystroke, a nice search bar always renders some possible options the user could be looking for. The core ideology behind having this feature is — do as much work as possible for the user!
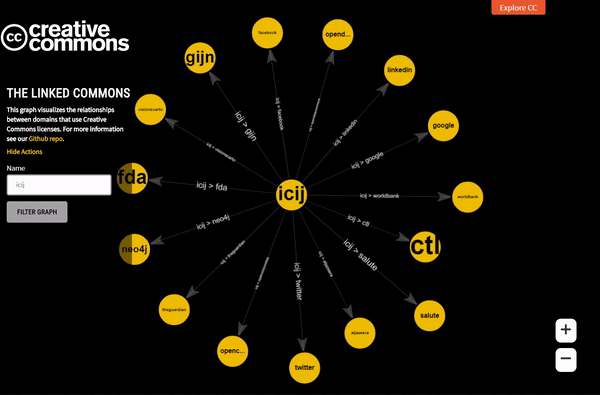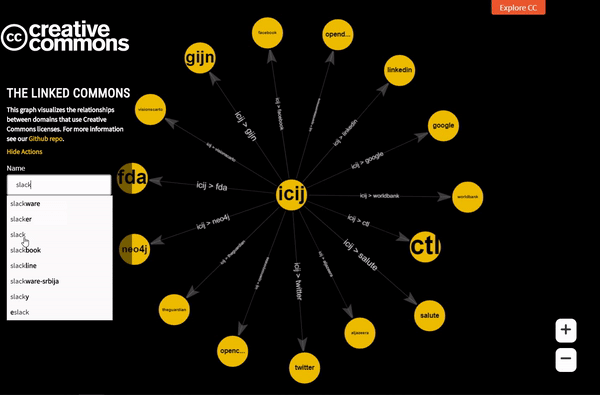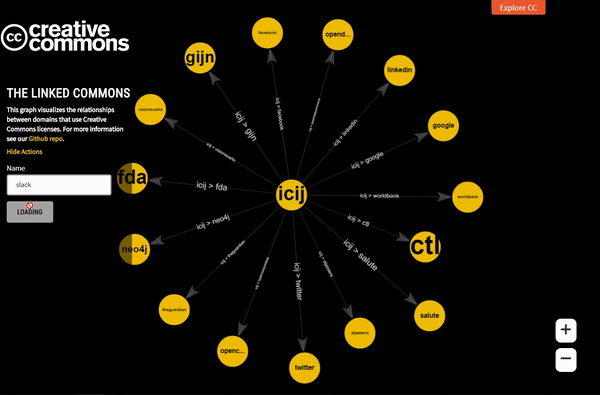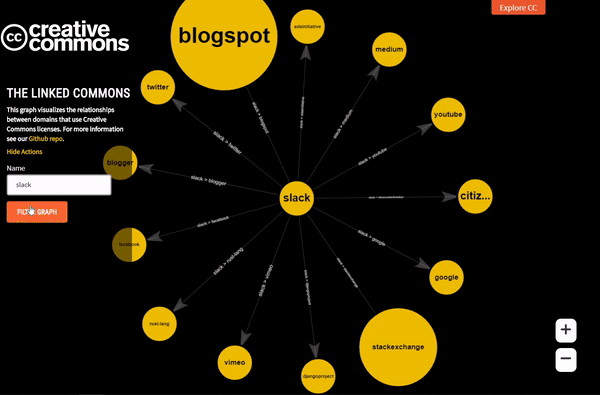
Autocomplete feature in action
Motivation
One of the newest features integrated last month into Linked Commons is Filtering by node name. Here a user can search for his/her favourite node and explore all its neighbours. Since the list is very big, it was self-evident for us to have a text box (and not a drop-down) where the user is supposed to type the node name.
Some of the reasons why to have "autocomplete feature" in the filtering by node name -
Some of the node names are very uncommon and lengthy. There is a high probability of misspelling it.
Submitting the form and getting a response of “Node doesn’t exist” isn’t a very good user flow, and we want to minimise such incidents.
Also, on a side note giving a search bar to the user and giving no hints is ruthless. We all need recommendations and guess what linked commons got you covered! Now for every keystroke, we load a bunch of node names which you might be looking for. ;)
Problem
The autocomplete feature on a very basic level aims to predict the rest of a word the user is typing. A possible implementation is though the linear traversal of all the nodes in the list. It will be having a linear time complexity. It’s not very good and it’s very obvious to look for a faster and more efficient way. Also, even if for once we neglect the time complexity, looking for the best 10 nodes out of these millions on the client's machine is not at all a good idea; it will cause throttling and will result in performance drops.
On the other hand, a trie based solution is more efficient for sure but still, we cannot do this indexing on the client machine for the same reasons stated above.
So far, it is now apparent that we implement this feature on the server and also aim for at least something better than linear time complexity.
A non-conventional solution
We could have used Elastic Search, which is very powerful and has a ton of functionalities but since our needs are very small we wanted to look for other simple alternatives. Moreover, we didn't want to complicate our current architecture by adding an additional framework and libraries.
Taking the above points into consideration we went ahead with the following solution. We store all nodes data into an SQL dB and search for all the nodes whose domain name pattern was matching to the query string. After slicing the query set and other randomization we sent the payload to the client. To make it more robust, we are caching the results in the frontend to avoid multiple calls for the same query. It will surely reduce the load from the server and also give a faster response.
Results
To make sure our solution works well, we performed load tests, checking that any response time does not exceed 1000 ms. We used locust which is a user load testing tool. We simulated with 1000 users and 10 as Hatch rate.
The following test is performed on the local machine to ensure that the server location isn’t affecting the results.
Here are some aggregated result statistics.
Field Name
Value
Request Count
23323
Failure Count
0
Median Response Time
360 ms
Average Response Time
586.289 ms
Min Response Time
4.03094 ms
Max Response Time
4216 ms
Average Content Size
528.667 ms
Requests/s
171.754
Max Requests/s
214
Failures/s
0
Next steps
In the next blog, we will be covering the long awaited data update and the new architecture.
Conclusion
Overall, I enjoyed working on this feature and it was a great learning experience. This feature has been successfully integrated to the development version, do check it out. Now that you have read this blog till the end, I hope that you enjoyed it. For more information please visit our GitHub repo. We are looking forward to hearing from you on linked commons. Our # Open Source Zulip channel doors are always open to you, see you there. :) [updated 2025-09-23]