Linked Commons is a visualization project which aims to showcase and establish a relationship between millions of data points of licensed content metadata using graphs. Since it is the first blog of this new series, let’s discuss the core ideology of having this project and then about new features. Development of all components mentioned in this blog is complete and has been successfully integrated, so do check out the development version. Happy Reading!
Motivation and why does visualization matter?
The number of websites using creative commons licensed content is very huge and growing very rapidly. The CC catalog hosts these millions of data points and each node contains information about the URL of the websites and the licenses used. One can surely do rigorous data analysis, but this would only be interpretable by a few people with a technical background. On the other hand, by visualizing data, it becomes incredibly easier to identify patterns and trends. As an old saying, a picture is worth a thousand words. That’s the core ideology of the Linked Commons, i.e. to show the millions of licensed content metadata and how these nodes are connected in a visually appealing form on the HTML canvas like a picture.
Task 1: Code Refactoring
My first task was to refactor the code and migrate it to react. The existing codebase had all core functionalities, but we wanted to make it more modular, improve the design, code readability, and reduce complexity. This will help us maintain this project in the long run. Also, it will be easier for the community to contribute and understand the logic.
Task 2: Graph Filtering
Need for Filtering Methods
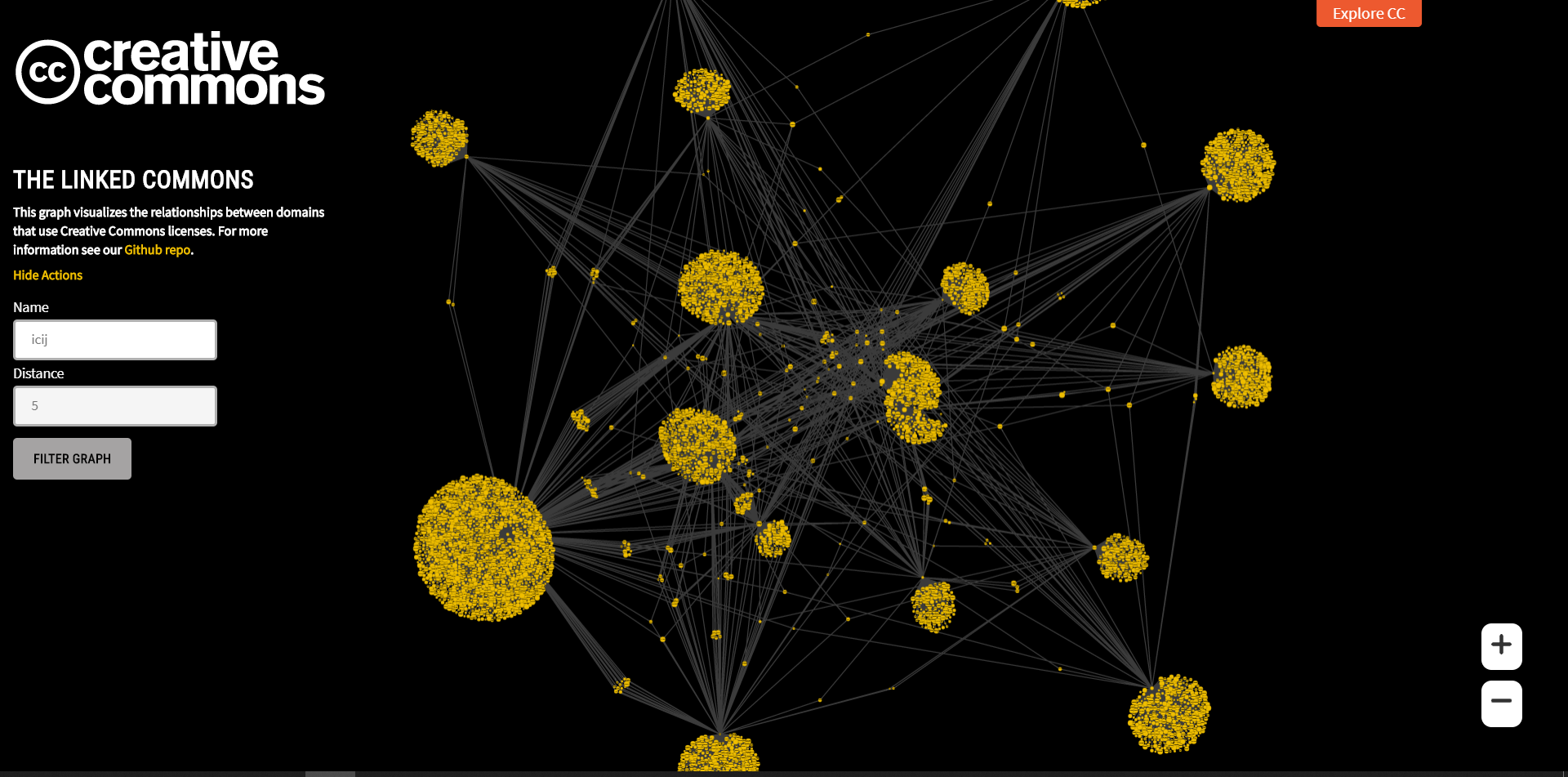
Pic showing clustors of a Graph with 9982 nodes 5000 links
The aggregate data that cc catalog has is in hundreds of millions. Rendering a graph with these many nodes will be a nightmare for the browser’s rendering and JavaScript engine. Just like we divide any standard textbook into chapters, we thought about adding filtering options that enable the user to retrieve precise information according to certain criteria selected by them. Hence, we need to have a way in which we can filter the aggregate data into smaller chunks.
What filtering methods?
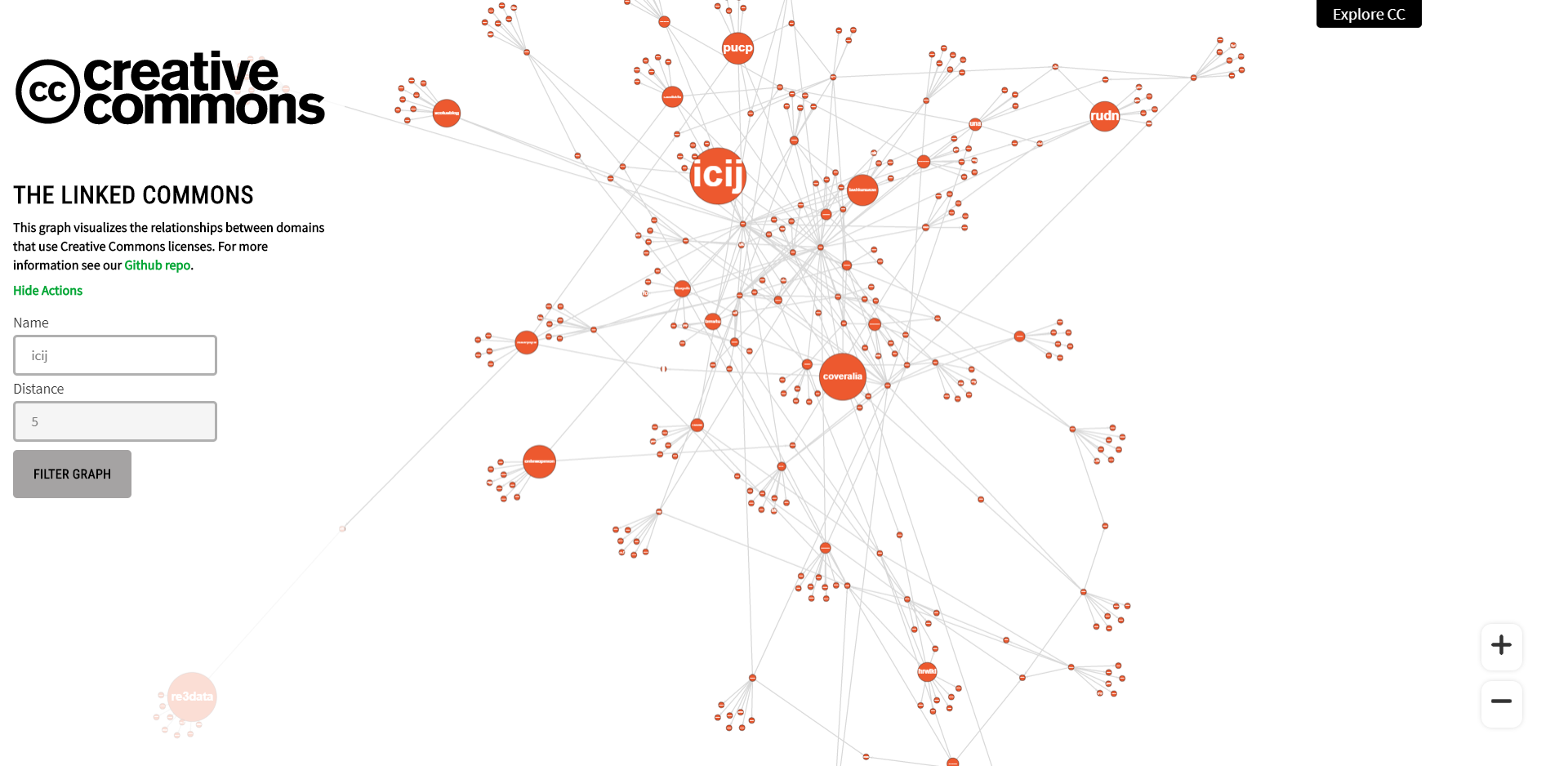
After brainstorming for a while, we converged and agreed to have filtering based on node name and distance. The primary reason behind this was, it is kind of basic that a person would like to look for his/her favourite node and its neighbours. This is not the end for sure, and many more filtering methods will be added, maybe with the support of chaining one after another. This is just a baby step!
Server-side Filtering vs Client-Side Filtering?
Now that we know on what query params the filter should work, we need to decide where to do the filtering. Should we do it on the client machine or do it on our server and pass the processed and filtered data to the client? In any filtering method, we need to traverse the whole graph. The JS engine in the browser is doing rendering stuff, complex calculation, etc. With all these processes, doing a full traversal of the dataset having more than a million nodes is going to take a lot of time and memory. The above claim assumes that we have a moderately dense graph. On the other hand, another strategy to accomplish graph filtering could be to delegate that load to a server, and the client’s browser can ask for a fresh copy of the filtered data whenever needed. As mentioned above the client-side filtering has serious shortcomings and user experience won’t be very good with browser freezing and frame drops. So, that's why we decided to go with the latter option i.e server-side filtering.
Filtering In Action
Task 3: New Design
My third task was to upgrade the front-end design of the project. It now has a very clean and refreshing look along with the support for both light and dark theme. Check out our webpage in dark mode and do let us know if it saves your PC energy consumption (As claimed by some websites). Now you all can visit the Linked Commons webpage at mid-night too, no strain to the eyes. ;)
Linked Commons - Light Theme
Next steps
In the next two weeks, I will be working on the following features.
Implement suggestions API on the server and integrate it with the frontend
Update the visualization with a more recent and bigger dataset
Conclusion
Overall, it was fantastic and rejuvenating experience working on these tasks. Now that you have read this blog till the end, I hope that you enjoyed it. For more information visit our Github repo. We are looking forward to hearing from you on linked commons. Our # Open Source Zulip channel doors are always open to you, see you there. :) [updated 2025-09-23]